
Why do we test?
Software development is a collaborative effort. You bring in input from customers, managers, developers, and QA and synthesize a result. You do this because mistakes in requirements or architecture are expensive, possibly leading to lost sales.
When we develop products we want them to be successful. We want our customers to buy, enjoy, and recommend our products or services. In other words, we want to build quality products. In this case, quality means four inter-related things:
- Compliance quality– Can we demonstrate that the software fulfils its requirements?
- Intrinsic quality – is the product robust, reliable, maintainable, etc?
- Customer-perceived quality – How does the customer react to our product on a sensory, emotional level?
- Fitness for Purpose– does our product fulfil the stakeholder’s needs?
Which of these types of quality is most important to us depends a lot on our problem domain and the goals and driving forces of our business.
We take considerable pains (but not enough in most cases – but that’s a different argument!) to analyse, design and implement our system to meet our quality goals. Unfortunately, engineers are not perfect. They are under increasing pressure to deliver more features, in less time, and as a consequence they do not have the luxury of time to learn the problem domain, or examine their solutions.
As a consequence engineers make mistakes. These mistakes appear as corruptions in the translation from a specification (what to do) to an implementation. An error can occur wherever we translate a specification to an implementation.

Figure 1 – Typical errors in embedded systems
This raises an important question – how to you measure confidence in a product? That is, how do we know the quality of our product is good enough that we can release it for production?
The simple answer is: we test.
Or, perhaps more correctly: we perform validation and verification activities.
A note on definitions
for this article I will use the following meanings for validation and verification. I’m being explicit because every development group I’ve spoken to uses a different word (or combination of them!) to describe the same concepts.
Verification
Verification confirms some predicate about the system. Verification confirms the existence (or non-existence) of, state of, value of, some element of the system’s behaviour or qualities. Put simply, verification asks questions that yield a yes/no answer.
Validation
Validation is focused on assessment of system predicates, rather than their confirmation. In other words, validation asks the question: should the system actually perform a particular behaviour or have a particular quality. Validation assesses the system in terms of good/bad.
Just to confuse matters, I will use the terms validation and verification (V&V) and testing interchangeably.
Introducing the “Swiss Cheese” approach to testing
Testing is often the last resort for finding mistakes. A requirements specification is produced, a design created and implemented. Then, testing is used to verify the design against the requirements and to validation both the design and the requirements. Testing cannot be a perfect technique. Done poorly, many faults will still remain in the system.
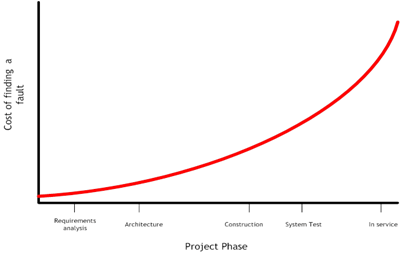
Figure 2 – The cost of finding – and fixing – a bug
This is a well-known graph. It shows the (relative) cost of finding – and fixing – a fault in a system throughout the lifecycle of the project. In simple terms it shows that it can cost orders of magnitude more to find and fix a problem at the end of the development lifecycle than during the early stages; and even more once the project is in service.
A key point to note is: Testing does not improve your software. Testing is not about proving the software has no faults. (This is impossible!) Testing is a quality improvement technique. It provides evidence – in the form of testing metrics – to support the engineers’ claims (that their design works and is valid).
Just testing the software doesn’t make it better:
• Testing just identifies the faults
• Fixing the faults makes the software better (although, not always!)
And simply writing more tests won’t make your software better – You must improve your development practices to get better software. The more testing you do the better your product confidence should be – provided you perform good tests!
Closing the holes (improving) testing requires effort and costs money. Moreover, the more sophisticated, rigorous and detailed you make any particular testing technique the more it will cost. In fact, there is a non-linear increase in the costs of applying a technique:
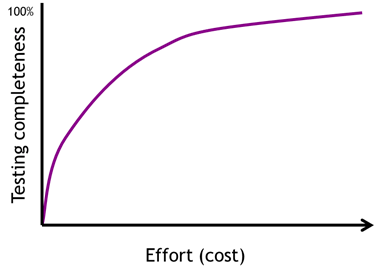
Figure 3 – The cost of improving any particular testing technique
Trying to ‘perfect’ one technique – for example, black-box unit testing – is not a cost-effective way to gain product confidence. Using multiple, independent techniques (each playing to their own strengths) is far more effective.
The “Swiss Cheese” approach to testing uses multiple techniques, each with a different focus. The techniques are applied with the clear knowledge that no technique is perfect (nor should it be) but the flaws in any one technique do not overlap (much!) with the flaws of another layer.
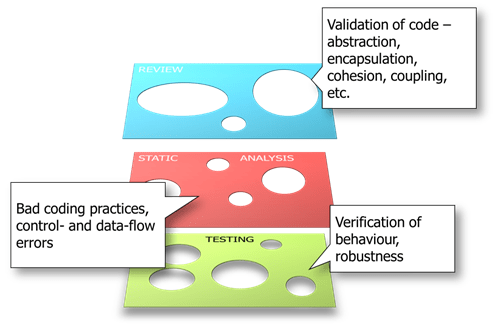
Figure 4 – the Swiss Cheese model
The Error-Fault-Failure chain

Figure 5 – The Error-Fault-Failure chain
The Error-Fault-Failure chain shows the propagation of mistakes through the development lifecycle. Mistakes made by engineers lead to errors; errors are manifested as (latent) faults – code just waiting to go wrong!; in some cases a fault may lead to the system deviating from its desired behaviour – a failure.
Clearly finding latent faults before they become failures is more effective than just trying to detect failures; and finding errors that lead to latent faults is more effective still.
Dynamic Testing
Dynamic Testing focuses on identifying failures.
Black box testing is concerned with measuring the correctness of the system’s behaviour, performance or other quality. Black box testing is therefore primarily a verification technique.
Black box testing tests specification without knowledge of implementation. The unit under test is stimulated via its interface(s). Black box testing requires a complete, consistent unambiguous specification to test against.
Black box testing typically involves isolating a subset of the system and executing it in isolation in a simulated environment.
White box testing, or Coverage testing is about establishing confidence in the structure of the code. Coverage testing focuses on the rigour of the dynamic testing process.
Coverage testing is not concerned with verification or validation but with ensuring all code has been adequately exercised. The motivation is that code that has not been executed during testing may have faults in it; and it we don’t check that code the faults may manifest themselves when the system is in service.
Dynamic testing involves execution of the software in a (simulated and, later in the develop cycle, live) environment.

Figure 6 – Environments for executing dynamic tests
Dynamic testing does not find latent faults effectively. The amount of effort required to find potential failures in your code is extremely high.
Static Testing
Static testing, using Static Analysis tools, look for latent faults in code.
Static Analysis tools is a generic description for tools that aid verification without having to execute software.
There are (currently) more than three dozen tools on the market. Most are commercial tools, but there are many academic-based tools. There are a small number of free- or share-ware tools available, also.

Figure 7 – Categorisation of static analysis tools
These tools are nearly always language specific – that is, there are tools for C, C++, Java, etc.
They are commonly based on compiler technology, since the initial stages of static analysis are the same as those required for compiling code.
Pattern Matching tools
Pattern matching tools look for dangerous expressions. .Grep-like tools search for known incorrect patterns. They can be useful for simple latent faults and enforcing style standards in code.
Semantic Analysis tools
Semantic analysis tools are based on compiler (parser) technologies. They use the first stages of the compilation process to build an Abstract Syntax tree. The parse tree in enhanced with additional semantic information. The enhanced Abstract Syntax tree is then evaluated against a rulebase looking for violations.
Symbolic Execution tools
Symbolic execution tools look at data-flow analysis. Symbolic execution tools are less concerned with language level constructs and instead focus on how data is created used and destroyed.
Abstract Interpretation tools
Abstract Interpretation involves treating the code as an abstract mathematical characterisation of its possible behaviour. The model is then executed to examine its behaviour (for faults).
There is a considerable overlap between Abstract Interpretation, Symbolic Execution and Semantic Analysis in most commercial tools.
In practice most commercial tools use a number of techniques, both to provide better analysis and also to minimise the shortcomings of each of the techniques.

Figure 8 – There is considerable overlap between commercial SA tools
Most tools will have a bias towards one particular technique. When choosing a tool it is prudent to consider where the tool’s bias lies and whether that suits your usage of static analysis techniques. In some cases you may consider buying more than one static analysis tool.
Static Analysis tools focus on the use (or misuse) of programming language. They cannot make any meaningful judgements on design issues – for example cohesion, coupling, encapsulation of abstraction flaws in the system’s design.
Review
Judgements on design, system evaluation, measures of good/bad, and other aspects of validation cannot be automated easily. The most effective technique to find mistakes in these aspects is human review.
In the past reviews have focused on (attempting to) find latent faults in code by detailed inspection. Unfortunately, this is something humans are particularly bad at so it becomes an activity that either 1) takes a long time or 2) is very poorly executed (that is, merely given lip-service).
The strength of human review is the ability of humans to build abstract representations and evaluate them. Thus reviews should focus on the things tools can’t automate – design, modularisation, evaluation, intrinsic quality, etc.
Applying the Swiss Cheese model
In the Swiss Cheese model no technique has to be perfect. Each technique is used for its strengths with the knowledge faults not found by one technique may be caught by another.
Some faults will still get through, though!

Figure 9 – In this Swiss Cheese approach no technique needs to be perfect
The aim is to spread our effort across multiple techniques to get the most effective result for the minimum effort.
Consider: If we are not particularly diligent with any particular technique, such that each technique only finds 50% of the mistakes at each level, with three different levels we have the potential to find 87.5% of the mistakes in the system. And this without disproportionate effort in any area. (and yes, I know this is a somewhat optimistic and simplistic scenario)

He specialises in C++, UML, software modelling, Systems Engineering and process development.
- Practice makes perfect, part 3 – Idiomatic kata - February 27, 2020
- Practice makes perfect, part 2– foundation kata - February 13, 2020
- Practice makes perfect, part 1 – Code kata - January 30, 2020
Glennan is an embedded systems and software engineer with over 20 years experience, mostly in high-integrity systems for the defence and aerospace industry.
He specialises in C++, UML, software modelling, Systems Engineering and process development.
Mr. Carnie,
May I have permission to reuse some of the figures in this blog article in a whitepaper I am writing on using IBM Rational tools for DO-178B/C software development?
Regards,
Daniel R. Barbour, CTO CertTech LLC
Of course; but please credit the source.
Hello Mr. Carnie,
an interesting blog.
But one hint from my side:
I know only the fault-->error-->failure chain, e.g. : https://i2.wp.com/www.vlsifacts.com/wp-content/uploads/2017/11/Fault-error-failure.png and also in the ISO26262
Regards,
Simon Schlachta