
Contents
What is Revision Control?
Revision control is the management of multiple revisions of the same unit of information. The focus is on controlling access to the artefact; and recording the history of changes.
Revision Control is variously known as version control, source control, source code management and several other titles.
Revision control has its roots in the management of engineering blueprints and paper documents. Today, any practical application of Revision Control requires the use of specialist software tools.
Artefact Identification
The core to revision control is the artefact. An artefact is a unique unit of information that may change over time (or not – some artefacts are deliberately unchanging – see below). Every revision-controlled artefact is identified by a unique name made up of:
Artefact Name
The artefact’s name represents a human-readable identifier. This is typically how the artefact is referred to during the development process. The Artefact’s name is constant – that is, it does not change.
Revision identifier
The revision identifier is used to track the history of the information. It is usually a number (e.g. 1.1); the highest number is the most recent version (revision)

Figure 1 – The artefact identifier reflects the name of the unit of information and its history
As the artefact is modified (revised) the revision identifier is incremented and a new entity is created (see Figure 1). Thus, artefact MyDoc v1.0 is a different entity to MyDoc v1.1 since it contains different contents. One of the principles of revision control is that this process is hidden from the user, and they only see the most recent version, unless they explicity choose to access the artefact’s history (by accessing a previous revision).
Problems with ‘file system’ Revision Control
The simplest form of revision control is to use the directory system on your computer. Each revision of a product is kept as a separate directory on the disk (Figure 2). This is a simple technique but is rarely very effective.

Figure 2 – Storing file revisions using a file system is rarely effective
Since few file systems have a history facility built in, each revision must result in the storage of multiple (complete) copies of each artefact.
Normally, using a file system as a repository implies using a networked file server. Most modern file systems will recognise that a file is open for edited and restrict access (see File Locking, below). However, to improve responsiveness most users will make a local copy of their ‘working files’. This can lead to a problem known as ‘Latest-write wins’. This means, if multiple developers copy the same file to modify it (usually in different ways) then each copy their modified file back to the server this can lead to the loss of any previous changes; and only the last developer to save has their revisions included. Clearly, to control access to each file requires careful management to ensure consistency. Such systems, requiring process and procedures to retain consistency are easy to abuse, particularly in the heat of the rush to delivery.
Another problem comes when artefacts are shared between systems; especially if each product will make different demands, and require different modifications, to the artefact.
Using your file system for source control is, at best, adequate for one-man projects.
Revision Control Systems
For anything more than trivial revision control (for example, with more than one developer) then a Revision Control System (RCS) is required.
A Revision Control System (also known as a Version Control System – VCS) is a piece of software that acts as an archive for artefacts. The RCS stores the latest version of the artefact and all revisions. The developer can take latest revision (often called the ‘tip’) or any named revision.
Typically, the RCS stores first version of artefact, plus changes between one revision and the next (known as ‘deltas’). Artefact version numbering is usually automatically performed by the tool.
Access control
To ensure integrity of artefact revisions access control is required. Typically this involves locking the file against changes.
Acquiring the lock is referred to as Checking Out.
Committing the change (releasing the lock) is referred to as Checking In.
There are two common methods for achieving access control: File locking and Revision Merging
File locking
In a file locking system only one developer has write access to the artefact (Figure 4). Other developers will have read-only access to the current (stored) version. The file is only available again once it is checked back in.
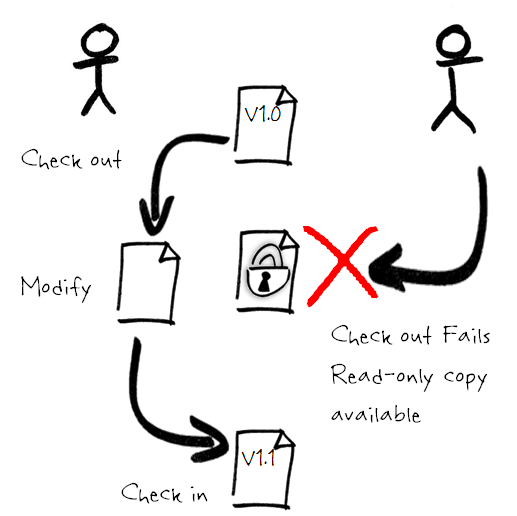
Figure 4 – File locking allows only one developer at a time to modify an artefact.
File locking avoids complex merges due to large-scale changes since only one developer has access to the file and the ‘merges’ are essentially the new changes made by the developer.
Because a file may be checked out for a significant time developers may be tempted to simply circumvent the system
Revision Merging
Most systems allow multiple check-outs of the same file (see Figure 5).
If the file is checked-out multiple times the first developer to check-in always succeeds.

Figure 5 – Revision merging allows multiple check-outs on an object
Subsequent check-ins must merge their changes into the current revision. For simple merges this may be performed automatically by the RCS software. More complex merges may (and typically do) require human intervention.
Revision Control System Configurations
Revision control systems are designed to allow multiple users to access and modify artefacts from any location, either locally or across a network. There are two basic configurations of RCS – centralised and distributed. Each has its own merits; and the choice of RCS depends on the type of project being developed.
Centralised database systems
In a centralised system there is one master reference copy of all artefacts (Figure 6). Clients access the artefacts by making copies of a subset of central archive. This subset is a ‘view’ on the repository known as a Workspace. The workspace acts as an additional form of access control. The client is free to modify any artefact within their workspace, but may not modify anything not in their workspace (in fact, it should not be visible to them). Workspaces allow CM Managers to restrict access of staff to only the artefacts that are relevant to them.
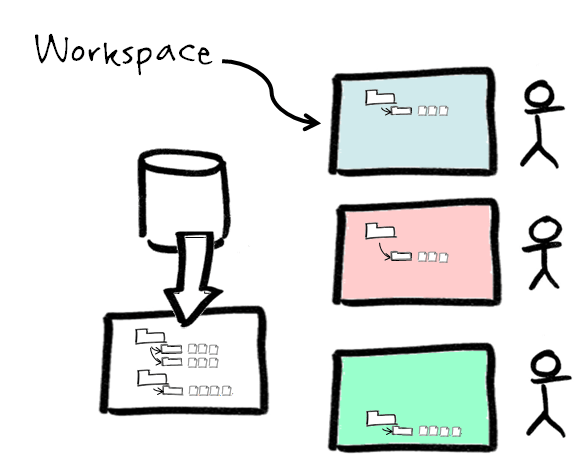
Figure 6 – In a centralised system clients view a subset of the central repository
Centralised systems are best suited to geographically-close, commercial development projects, keeping all the company’s artefacts (which comprise their intellectual property) in a central location (for ease of back-up, etc.).
Distributed database systems
In a distributed system each client’s workspace is a bona fide repository. Each client has a full copy of the archive, complete with all revisions (Figure 7). The client is free to modify the database as they see fit.
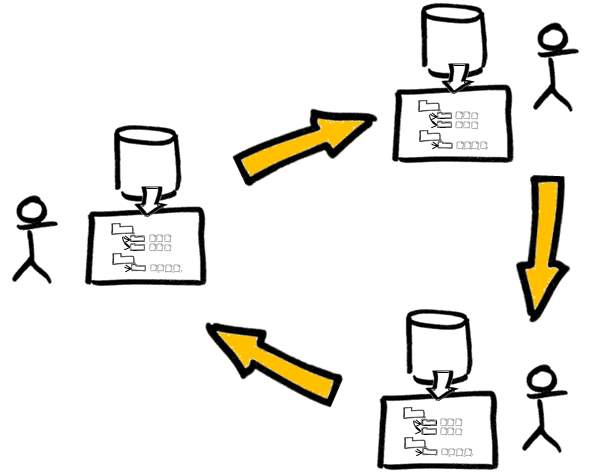
Figure 7 – Multiple versions of the archive exist in a distributed system
Copies of the archives are kept synchronised with periodic updates (known as patches) sent between each of the RCSs.
Distributed database systems are widely used for open source software development. They are well suited to developments that may be geographically distant and being modify according to widely differing requirements.

He specialises in C++, UML, software modelling, Systems Engineering and process development.
- Practice makes perfect, part 3 – Idiomatic kata - February 27, 2020
- Practice makes perfect, part 2– foundation kata - February 13, 2020
- Practice makes perfect, part 1 – Code kata - January 30, 2020
Glennan is an embedded systems and software engineer with over 20 years experience, mostly in high-integrity systems for the defence and aerospace industry.
He specialises in C++, UML, software modelling, Systems Engineering and process development.
Pingback: Sticky Bits » Blog Archive » Fundamentals of Configuration Management
A good clear article on the basics of version control.
It should be noted that all of a project's "artefacts" must be controlled and not just its source code. You allude to this of course, but a lot of VCS systems are designed to handle raw text files only, which makes the control of binary file types such as word processor documents, target binaries (for release control), software tools, etc. impractical. This leads to multiple version control systems and methods being used, which then compounds the configuration management problem.
Another problem with the type of version control system that you describe is that the granularity of change control is at the whole file level. This raises challenges with the versioning of artefacts that exist at a finer level of granularity, such as requirements, individual elements in a UML model, or even paragraphs in a document. Careful choice of the desired level version control granularity (e.g. by limiting the volume of individual file content) or the use of disparate version control techniques (as best suits each type of controlled artefact) is about the only solution.
The integration of multiple version control techniques into a homogenius CM system is the challenge that ALM (application life-cycle management) addresses.