
In the previous article we looked at the memory consistency problem that occurs when writing multi-threaded code for modern multi-processor systems.
In this article is we’ll have a look at how we can solve the sequential consistency problem and restore some sanity to our programming world.
Contents
An example
A simple example helps when faced with a complex problem. Below we have two thread classes – a Producer, which creates data and inserts it onto a stack; and a Consumer, that retrieves data from a stack. This pattern is very typical in embedded systems; particularly where the Producer and Consumer run at different rates.
(The reason for using a stack, rather than the more-common FIFO queue, is simply one of space – I want to limit the amount of source (and particular assembly) code I present. It’s easy to get lost in the noise if you’re not careful)

Below is our basic stack implementation. The stack is a simple array. The count member is used to ensure data isn’t inserted onto a full stack; or read from an empty stack.

On the face of it the Stack code looks sound – the Producer thread only calls Stack::push(), the Consumer thread only calls Stack::pop() so there should be no interaction between the threads. A less naive inspection may conclude there is a problem with the stack array, since one thread is inserting to the array and the other thread is reading from the array. This gives us the potential for a data race.
Part 1 – No data races
A data race can be defined as follows:
When an expression in one thread of execution writes to a memory location and another expression in a different thread of execution reads or modifies the same memory location, the expressions are said to conflict. A program that has two conflicting expressions has a data race.
In our example the memory location is not the stack array (although the symptoms of this problem will be exhibited in the array) but the count variable, which represents the current top-of-stack . Both the Consumer and Producer threads modify the count. If there is any interleaving of program opcodes that could result in a write instruction being next to a read instruction there exists a data race condition.
To better understand the issue we have to look at the generated assembler code for the Stack. The assembly code in this article are ARM Cortex M Thumb2 instructions, generated by the arm-gcc compiler (with the optimiser turned off to enhance readability)

Notice that the modification of the count object is not a single operation – the read, modify and write operations are independent opcodes.
Also notice the count value is only read once, even though the source code states to read it twice – once on the check for full/empty and once when the stack array is accessed. A simple analysis by the compiler identifies that no program expression modifies the count between the two reads; so it ignores the second read (known as a redundant load)
If we trace a sample execution timeline it is trivial to demonstrate we have a race condition in our Stack.
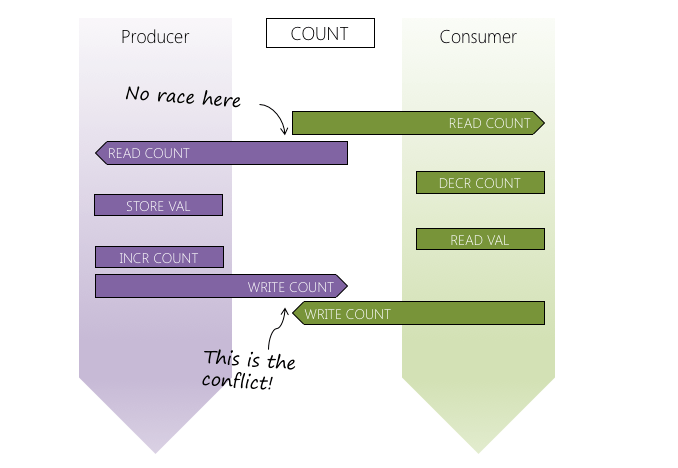
The two read operations don’t conflict. On almost all modern processors a read (load) is a single opcode; thus multiple threads reading from the same location should never cause us a problem.
The two interleaved writes are the issue in this case. The modification (increment) of the count made by the Producer thread is overwritten by the Consumer thread write. The next push() by the Producer thread is likely to overwrite the previous value.
Our first criteria for sequentially consistent code must therefore be: You cannot have a race condition in your program.
The easiest way to achieve this is to guarantee an ‘exclusive’ or ‘atomic’ read-modify-write operation on main memory objects. A normal object does not necessarily provide that guarantee (it may happen on some processor families, but not on others). Therefore we are required as programmers to tell the compiler that an object is ‘special’ and requires different operations for read / write compared to normal objects.
Part 2 – No, volatile doesn’t help
The volatile qualifier indicates to the compiler that the object may change outside the program flow-of-control; therefore reads and writes on the object cannot be optimised out.

A naïve programmer may believe that this is the problem that is faced here – the count value in one thread does appear to be modified (by another thread) outside of its program statements.
Below is the assembler code for the volatile count object.

Notice that previously optimised-out reads are reinstated. However, the modification of count is still individual read, modify and write instructions; so this does nothing to prevent our race condition.
With the optimiser turned to a high level the compiler reorders code; so that it no longer aligns (easily) with program-statement order. Although the compiler is required to keep reads and writes on a volatile object in program order, there is no requirement to maintain program order between separate volatile objects; the compiler is therefore still free to re-order reads/writes on volatile objects with respect to each other.
Part 3 – No optimization. At all.
Below I’ve modified the count to be a C++11 std::atomic type. std::atomic is a template class that can be parameterised with any scalar type (that is, built-in type).
(There are type aliases for all the usual scalar types but there are so many of them, and they’re kind of clumsy, so it’s generally much easier to just use the template)

Atomic types are guaranteed to implement atomic (indivisible) read and read-modify-write operations on their underlying object.
Atomic types have a basic load() / store() access interface. There are also atomic read-modify-write operations available, for example fetch_add() and fetch_sub()as used here. Operator overloads for common manipulations are provided also (see later).
On the face of it, atomic types appear to yield the same attributes as volatile objects. However, atomic types provide a much stronger guarantee than volatile objects in multi-processor environments.
Load-acquire / Store-release semantics
std::atomics mitigate the problem of optimising transformations by simulating what are referred to as Read-acquire / Store-release semantics.
Load-acquire semantics is a property which can only apply to operations which read from shared memory, whether they are read-modify-write operations or plain loads. Acquire semantics prevent memory reordering of the read-acquire with any read or write operation which follows it in program order.
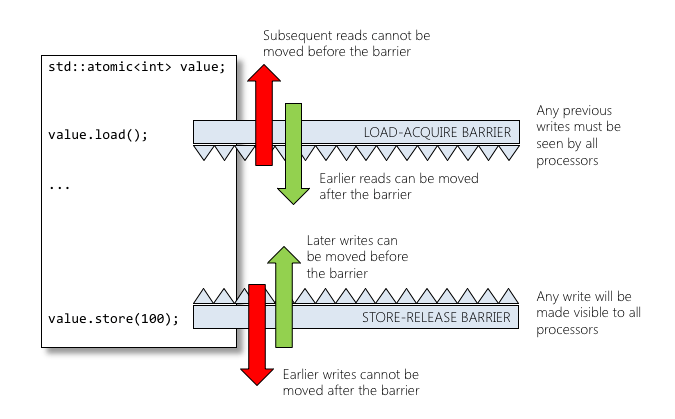
Store-release semantics is a property which can only apply to operations which write to shared memory, whether they are read-modify-write operations or plain stores. Release semantics prevent memory reordering of the write-release with any read or write operation which precedes it in program order.
Note that Read-acquire / Store-release are hardware and software concepts. In terms of software, these concepts prevent compiler reorganisation of std::atomic reads and or writes. From a hardware perspective these concepts require the compiler to issue synchronisation instructions (barriers, or fences).
Below, I’ve revised the Stack code to make use of the operator overloads provided by std::atomic types:

The cost of atomic types
Below is the ARM (v7 architecture) implementation for the std::atomic count.

Note the number of memory barriers (DMB statements) inserted by the compiler to ensure Sequential Consistency.
A DMB instruction ensures that all explicit memory accesses that appear in program order before the DMB instruction are observed before any explicit memory accesses that appear in program order after the DMB instruction. It does not affect the ordering of any other instructions executing on the processor.
The DMB instruction before each load ensures that any pending writes (remember, we can think of all main memory writes as asynchronous) are completed before the memory location is read.
On the ARM v7 architecture an atomic read-modify-write is implemented as serialised access via a spin-lock. A processor can request exclusive access to a memory location via a special load operation (LDREX). On write (STREX), if the processor has exclusive access its write will succeed; if not, the write will fail and the processor will have to repeat its exclusive load until it does get exclusive access.
It is important to realise that memory synchronisation actively works against hardware and software optimisations; performance of access is seriously degraded.
The default semantics for C++ std::atomics is Sequentially Consistency; as described above. In some (very specialist) corner cases it may be more efficient to explicitly relax the memory consistency model – for example to remove unnecessary memory barriers; or allow compiler read / write reorganisation. However, this is not a task to be undertaken lightly; and its application is beyond the scope of this article.
In practice, attempting to salvage a few clock cycles here-and-there by playing games with the memory consistency model is far more likely to lead to subtle functional problems that will be a nightmare to resolve. The sensible programmer will therefore stick with the standard sequential consistency model and improve performance by minimising the amount of data shared between units-of-execution.
Problem solved?
Even with the atomic count variable it is still possible to define an instruction interleaving that causes the program to fail.
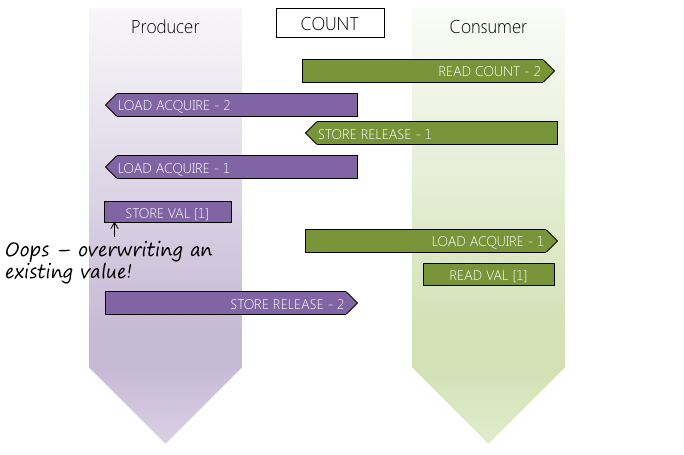
In this case we have to realise that adding or removing data from the stack requires two operations that must be performed as an atomic activity – the reading / writing of the data and the modification of the count.
To achieve this we have to look to a different mechanism – serialized access (but that’s for another article)
And finally…
This article reveals a simple set of guidelines for volatile and atomic objects:
volatile tells the compiler that the memory location can change outside the program flow-of-control. The compiler will therefore never optimize away reads or writes of the object. The compiler will never re-order reads or writes to a volatile object; but it makes no guarantee about ordering between volatile objects.
The use of volatile should be reserved for accessing hardware memory.
Using a std::atomic type provides all the guarantees of volatile objects but (by default) also guarantees the order of reads / writes between atomic objects. Implementations for atomic types do this by not only disabling compiler optimisations but also hardware optimisations.
The use of atomics should therefore be reserved for sharing data between units-of-execution; and their use should be minimised.

He specialises in C++, UML, software modelling, Systems Engineering and process development.
- Practice makes perfect, part 3 – Idiomatic kata - February 27, 2020
- Practice makes perfect, part 2– foundation kata - February 13, 2020
- Practice makes perfect, part 1 – Code kata - January 30, 2020
Glennan is an embedded systems and software engineer with over 20 years experience, mostly in high-integrity systems for the defence and aerospace industry.
He specialises in C++, UML, software modelling, Systems Engineering and process development.